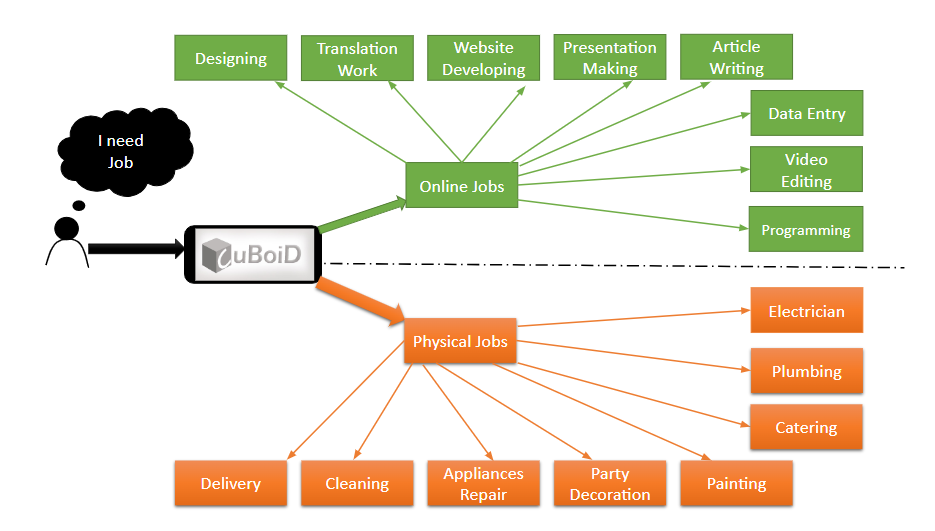
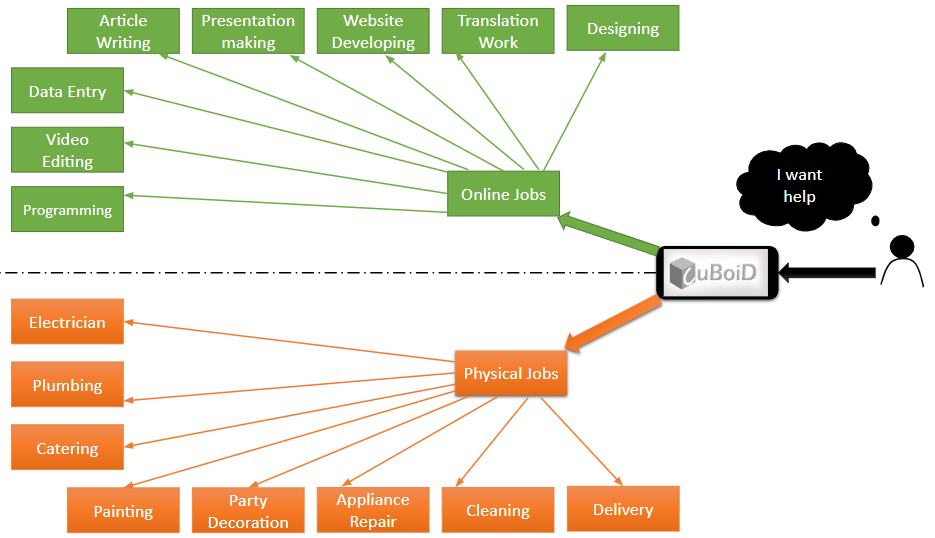
Cuboid is an mobile app, which helps people to search for local and online jobs in part-time on their own topic of interests and earn money.
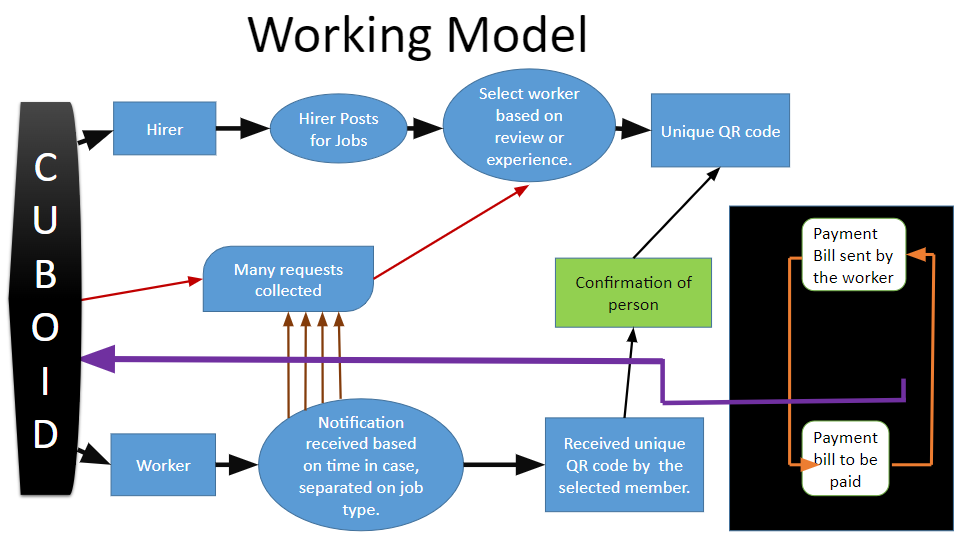
Cuboid helps people to get their work done by just peeking into the Cuboid and hire the best skilled person around you or just post for the job to get many requests from the skilled person around.
Cuboid has two sides ,One which allows hirer to post their job to be done on the Cuboid-wall and second ,worker search for the jobs on his/her area of interests.
Cuboid made the money transition easy by introducing the Cube-Wallet where people can send and receive money after the work have done.
Now people can spend there money in Cube-wallet to pay bills online ,recharging ,pay to shops and restaurants all around easily.
They can also share money among their friends and families.
This Google news scraper can scrape news based on a given keyword and the relevant searches are put in a CSV for the download.
Install necessary packages:
pip install requestspip install beautifulsoup4
Install the necessary libraries:
import requestsfrom bs4 import BeautifulSoupimport pandas as pd
Copy and paste the following code:
import requestsfrom bs4 import BeautifulSoupimport pandas as pd# Search Queryquery ='Indian Stock Market'# Encode special characters in a text stringdefencode_special_characters(text): encoded_text ='' special_characters ={'&':'%26','=':'%3D','+':'%2B','':'%20'}# Add more special characters as neededfor char in text.lower(): encoded_text += special_characters.get(char, char)return encoded_textquery2 =encode_special_characters(query)# the query given above as string encoded as special charactersurl =f"https://news.google.com/search?q={query2}&hl=en-US&gl=US&ceid=US%3Aen"# the complete URL with the queryresponse = requests.get(url)# html responsesoup =BeautifulSoup(response.text,'html.parser')# parsing the html codearticles = soup.find_all('article')links =[article.find('a')['href']for article in articles]links =[link.replace("./articles/","https://news.google.com/articles/")for link in links]news_text =[article.get_text(separator='\n')for article in articles]news_text_split =[text.split('\n')for text in news_text]news_df = pd.DataFrame({'Title':[text[2]for text in news_text_split],'Source':[text[0]for text in news_text_split],'Time':[text[3]iflen(text)>3else'Missing'for text in news_text_split],'Author':[text[4].split('By ')[-1]iflen(text)>4else'Missing'for text in news_text_split],'Link': links})# converting the responses into a data frame and writing it as a .csv file# Write to CSVnews_df.to_csv('news.csv',index=False)
This Python code scrapes app data from the Play Store and saves it as a CSV file. It extracts details like titles, ratings, descriptions, and more, for further analysis or comparison. with competitors.
You can scrape and download data from your competitors find out where they are lacking and use it to your advantage.
How to use it?
Open in your Google Collab
Replace the file_name with your actual file name
Replace the drive location with df_busu.to_csv(‘/content/drive/My Drive/file_name.csv’) # path to save your exported CSV file
Use Cases:
To do sentiment analysis
Get a better understanding of in-depth positive and negative feedback
You can also run this as a cron to get and connect it to Analytical tools such as PowerBI.
Import the required libraries
pip install google-play-scraperfrom google_play_scraper import appimport pandas as pdimport numpy as np
Enter the app package name from the Play Store URL, also mention the country, language, and the sort method you want:
from google_play_scraper import Sort, reviews_allus_reviews =reviews_all('app.rocket.com',# package name of the app you want to scrapesleep_milliseconds=0,# defaults to 0lang='en',# defaults to 'en'country='in',# defaults to 'in'sort=Sort.NEWEST,# defaults to Sort.MOST_RELEVANT)
Convert it into a data frame:
df_busu = pd.DataFrame(np.array(us_reviews),columns=['review'])df_busu = df_busu.join(pd.DataFrame(df_busu.pop('review').tolist()))# to displpay the top reviewsdf_busu.head()
# Data will appear here
Convert the data frame to CSV:
df_busu.to_csv('file_name.csv')# your filename herefrom google.colab import drivedrive.mount('/content/drive')# mounting google drive to storedf_busu.to_csv('/content/drive/My Drive/file_name.csv')# path to save your exported csv file
Check your drive, you’ll find the scraper review data in the specified “.csv” format.